 ]]>]]>
]]>]]>You can create the storage pool from your drives using the ‘Manage Storage Spaces’ applet in the Windows Control Panel. The drives must be uninitialized. To create a resilient space, you will need at least two drives in the pool, and three or more drives for parity-based resilience. Note: you can always add more drives to the pool later. Read a description of resilience types in this Microsoft article (it talks about servers, but the same applies to disks in local storage pools).
This will create an unformatted resilient (3 columns, e.g. 2 data + 1 parity) 80TB storage space, which does not require the whole capacity to be immediately available:
New-VirtualDisk -StoragePoolFriendlyName "YourPool" -ProvisioningType Thin -Interleave 32KB -FriendlyName Resilient -Size 80TB -ResiliencySettingName Parity -NumberOfColumns 3
NOTE: Pay attention to the -Interleave parameter. As described in this article,
it is important that when you format the disk in the next step, your file system uses
blocks whose size is evenly divisible by the interleave size.
This command will initialize the disk and assign it a drive letter:
Get-VirtualDisk -FriendlyName Resilient | Get-Disk | Initialize-Disk -PassThru | New-Partition -UseMaximumSize -AssignDriveLetter
Now you can format it to ReFS:
Format-Volume -DriveLetter XXX -FileSystem ReFS -AllocationUnitSize (32*1024*YYY) -SetIntegrityStreams $True
You must enable periodic integrity checks on your ReFS volumes. Not doing so means when you actually try accessing data many years later it might turn out to be corrupted on all replicas, and will not be recoverable anymore. Periodic integrity checks ensure all the replicas are correct, and if one replica is corrupted, scanner will use the other replicas to repair the data. So the data could only be lost if all replicas get corrupted between the integrity scans, which is much less likely.
To enable periodic checks, open Task Scheduler and find the scan tasks under
Microsoft\Windows\Data Integrity Scan. Then
NOTE: There’s a disagreement about the meaning of ReFS integrity checking settings
and no guidance from Microsoft that I could find. File integrity must always be Enabled
for ReFS to be able to detect corruption (it goes to the Event Log), but Enforced state
which is enabled by default will confusingly make partially corrupted files extremely
hard to recover. So until the situation is resolved, I recommend setting Enforced to False.
There’s a known issue with internal SATA drives on Windows that show up as ‘Removable’ and could only be used with BitLocker To Go. If you open BitLocker and your storage space is listed under ‘Removable’, you’ll need to follow the steps mentioned later in the same article for each physical drive in your pool (will likely need the Windows 8 and later option). A reboot might be required.
Once you’ve ensured, that your storage space is listed under ‘Fixed data drives’, you can encrypt it.
]]>The problem that led me into this sinkhole is an attempt to model biological rhythms. People sleep every 24 hours, the nature has a distinct 365 day cycle, and over a month the Moon goes from new to full and back. I wanted to capture that repetition relative to the current instant in time, which led to the Clock Problem:
Given the number of seconds since some moment T0 defined to be 0 days 0:00:00,
train a neural network to approximate the numbers you would see on a digital
clock. For example, -1 (second) would be 23:59:59.
Expecting that to be a dead simple task, I built an infinite dataset, that would sample a random instant in time from a period of 120 years, and fed it into a SIREN - neural network with sinusoidal activations.
To my surprise, despite playing with its frequency scale hyperparameter, the network, essentially, never converged.
I tried to use regular MLP with GELU activations, and got approximately the same result.
Research on the topic only brought Neural Networks Fail to Learn Periodic Functions and How to Fix It,
which, as you might have guessed it, did not really work on the Clock Problem.
Their x + sin(x) ** 2 activation only really worked when the number of full cycles
in the dataset was less than the number of paramters of the network, which
completely misses the point.
You can quickly see how inappropriate gradient descent is for the problem if we just simplify it a little. Let’s try approximating this trivial function:
FREQUENCY_SCALE = 31
def func(x):
return torch.sin(x * FREQUENCY_SCALE)
There is a a PyTorch module, that surely should solve the problem:
class Sin(torch.nn.Module):
def __init__(self):
super().__init__()
self.freq = torch.nn.Parameter(torch.randn(1))
def forward(self, x):
return torch.sin(self.freq * x)
Here, we only need to find the frequency, and the module will match our target function exactly! Let’s try it out:
net = Sin()
opt = torch.optim.SGD(net.parameters(), lr=0.0001)
BATCH_SIZE = 32
for batch_idx in range(1000*1000):
opt.zero_grad()
batch = (torch.rand(size=[BATCH_SIZE, 1], device=device) * 2 - 1) * 1000
out = net(batch)
expected = func(batch)
loss = ((out - expected) ** 2).mean()
loss.backward()
opt.step()
if batch_idx % 1000 == 0:
print(f'{loss.detach().cpu().item()}')
If you run this on your machine, you will see something like this:
0.775499165058136 1.3729740381240845 1.0878400802612305 0.7583212852478027 1.3061308860778809 0.6976296305656433 1.0671122074127197 0.9739978909492493 0.947789192199707
The loss just floats around 1 and never converges.
But we actually know the answer! Just insert this line:
net.freq.data = torch.tensor([31], dtype=torch.float32)
and your loss will turn to zero instantly:
0.0 0.0 0.0 0.0
sin?For the given x0 the derivative of our scaled sin with respect to freq
parameter is x0 * cos(x0 * freq). There are two things to note:
[-x0/freq*pi, +x0/freq*pi] interval.x0 * freq is closer to 2n*pi
or (2n+1)*pi for some n. And that value will vary wildly for different
samples in the batch.This is how the gradient of the freq paramter looks like on a large random
batch of points:
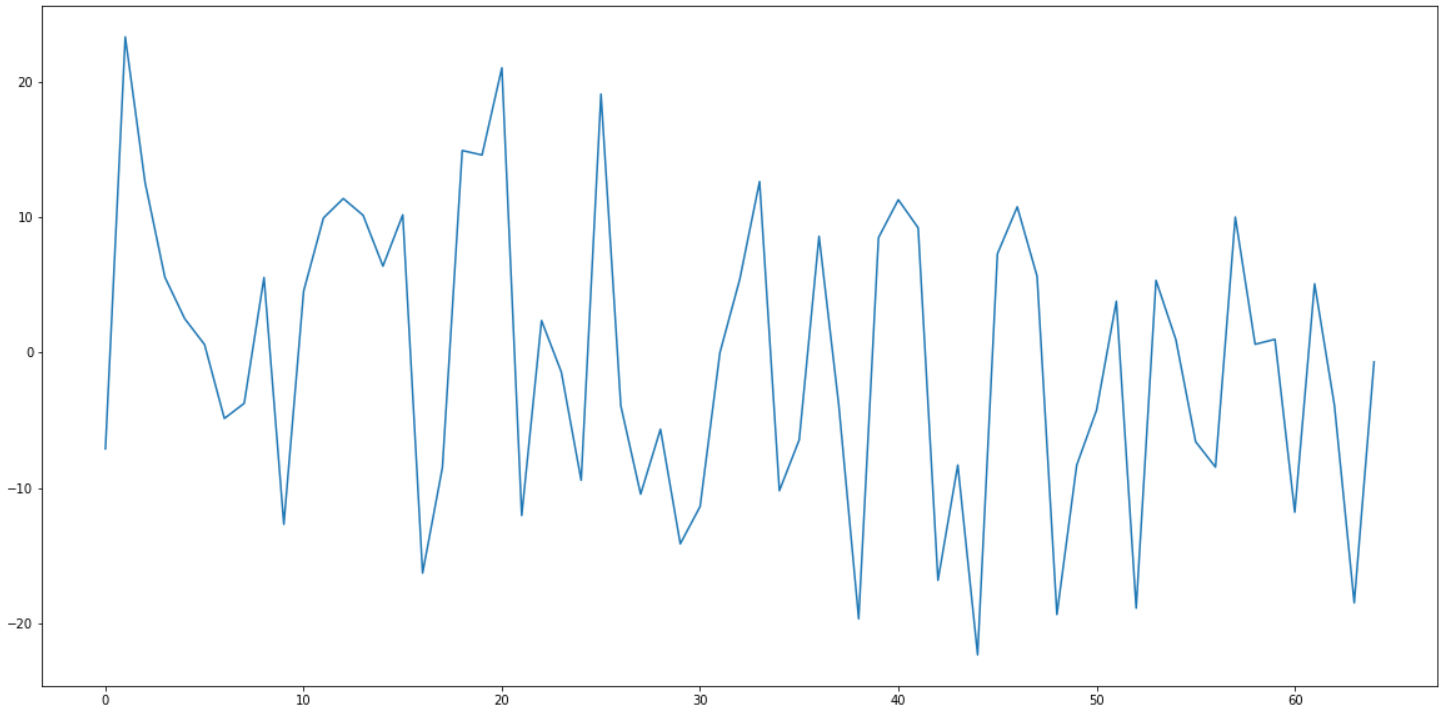
Can you spot the 0 at 31? As you can see, around it the gradient is all over the place.
Even in the immediate vicinity of 31, it does not behave well:
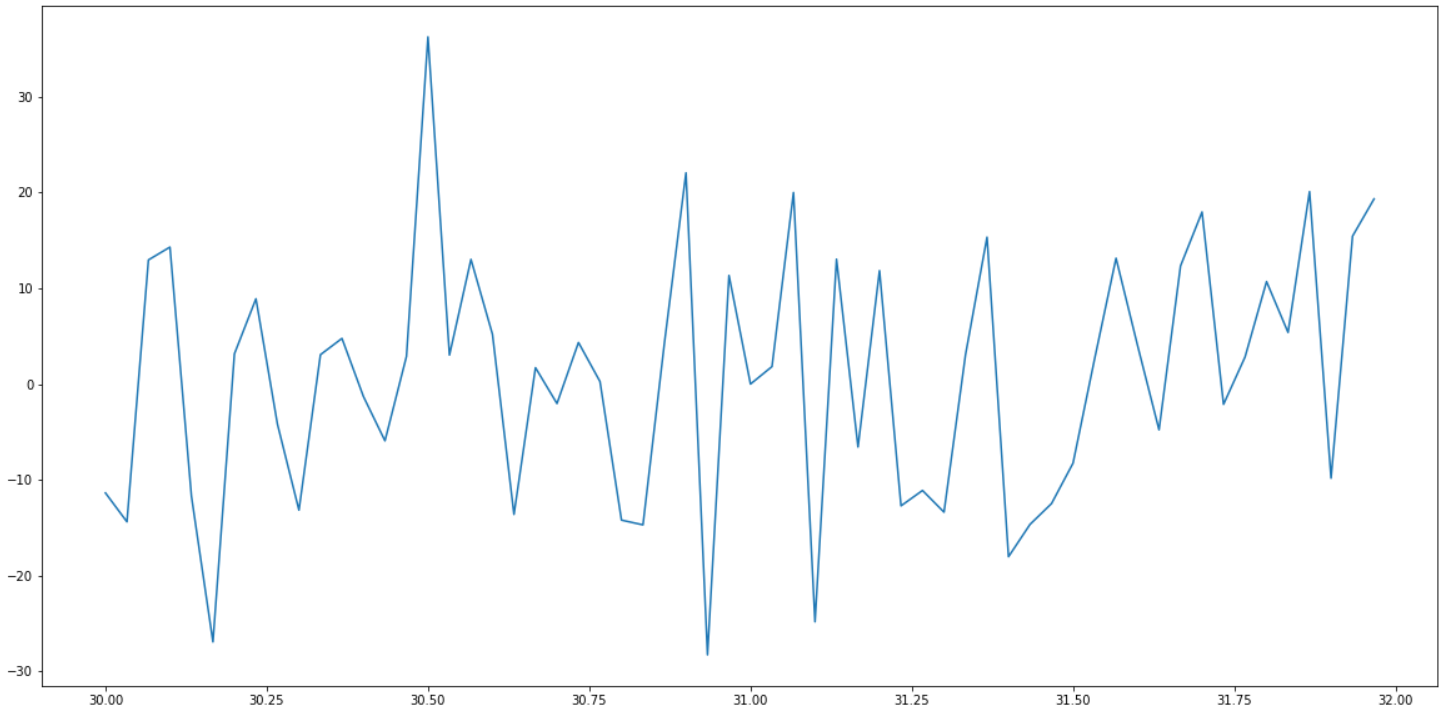
I don’t know. Perhaps a form of Fourier transform or a wavelet transform would help. Time to beef up on signal processing.
]]>
The app permission systems, that became popular with Android and iOS are a godsend. Now your bookreader app does not know your location, who your friends are, and can’t upload your private photos to their servers as a part of “analytics telemetry”.
Microsoft introduced a similar system with Windows 8 for the apps installed from the Microsoft Store, and expanded it in Windows 10 to any app packaged in a special way. So when you install an app from Store, you can be reasonably sure, that it does only what it is supposed to, right? Not so fast!
Facebook Messenger is famous for trying to obtain data. It used to insist on uploading your entire contact list to Facebook. Same goes for call and sms history. Text anyone in your phone? Here, can you spot the fine print:
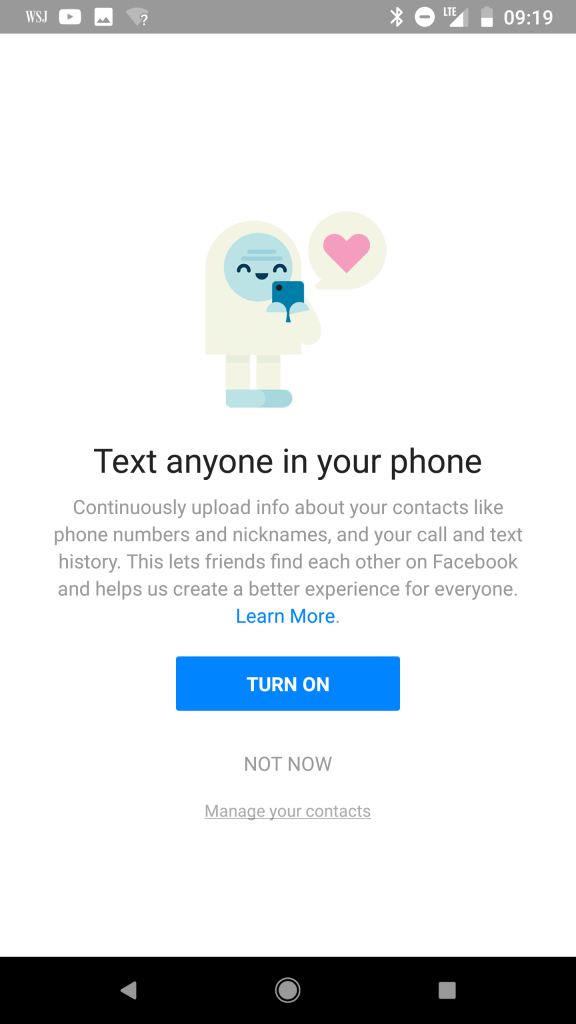
I am sure it is used only for your convenience (khe-khe, viral marketing, khe-khe).
Fortunately, even if somehow this option got overlooked, and you installed the app from Microsoft Store in 2018, you could ensure it does not have access to your data.
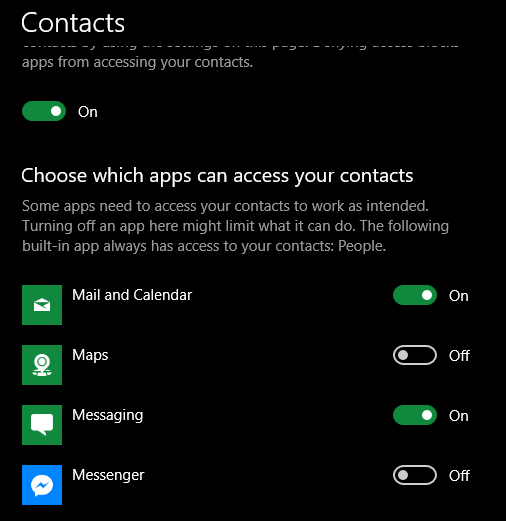
Similar permissions exist for call history, pictures, location, etc
No viral marketing or personalized ads for you, Mark!

That was all great until about 8 months ago. That is when I noticed, that one of the apps installed from the Store specifically for not asking any permissions whatsoever started showing a tray icon.
Tray icons are “classic” Windows APIs, that are not yet available to properly sandboxed Store apps. To show one the app had to obtain unrestricted permissions on your machine, same as the apps installed from a 3rd party.

So I went to the app’s page on Microsoft Store, and saw, that the new version has this permission. Which would be fine, if the Store would ask me if I want to give that app unrestricted permissions before updating it. But it did not.
Back then I reported the problem to Microsoft, thinking that they just probably overlooked it, and it is a bug, that will soon be fixed.
Coming back to Messenger: that app is notoriously buggy and did not work on my machine for a while, forcing to use the web version. I’ve been periodically launching it to see if Facebook fixed it, and today it finally started with a new login dialog. Which, of course, immediately made my inner paranoid very suspicious.
So I opened Messenger’s page on Windows Store, and saw this:
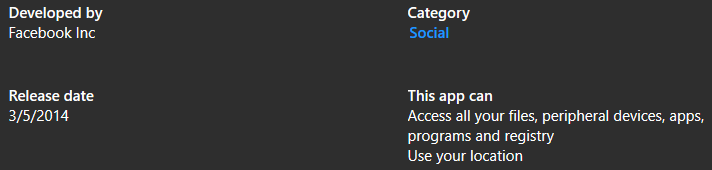
Looks like Windows Store silently updated it, expanding the permissions to give Facebook access to all my data without consulting with me first. Meaning the issue I reported nearly a year ago is still not fixed.
So, to conclude
All users, that installed your app before step 2 thinking it is 100% safe for them to use will be automatically updated to the latest version, and Store will give it a green ticket to user’s data.
P.S. The sad irony is I though it was a good idea to distribute a cryptocurrency mining app through the Store, as it would be a safe source for users. Until Microsoft banned them for “security”.
]]>What a shame.
UPD. You can now reinstall miner from Lost Tech Downloads
The whole idea of distributing it through the Store was for users to have a safe place to discover and download a cryptocurrency miner, as opposed to looking for one on random Internet forums with real risk to get malware in the package. And yet Microsoft banned miners from their store for “security”. Ironically, that’s the same policy section, that bans 3rd-party browser engines.

By banning miners, Microsoft is probably trying to prevent employees in companies worldwide from using corporate hardware for personal profit. But by doing so it also hurts consumers, who now have to take the above mentioned risks on themselves if they want to adopt this tech at home (my wife uses it as a “free” room heater). They could certainly just have a special mark on the app, and have a group policy denying the installation, that enterprises could enable, rather than denying the access to everyone.
Now I’ll have to spent a few days developing an alternative distribution system, and probably will loose a significant chunk of existing users. IMHO, that policy will hurt overall tech adoption too.
Download from Lost Tech Downloads
If you had one installed from Store, backup
C:\Users\<YOUR USER>\AppData\Local\Packages\LostTechLLC.MineETH_kdyhxf5sz30e2\LocalState\Mine.config
Then uninstall the Store one, and install the new one.
Copy your config backup and overwrite the new config location:
AppData\Local\Packages\LostTechLLC.MineETH_aptdcfzknqkda\LocalState\Mine.config
While upgrading Gradient to TensorFlow 1.15, I faced the need for a way to create a symbolic directory link with C#. Quick search on NuGet only gave 3 packages, none of which were cross-platform to a complete disappointment. So I decided to make my own.
Quick 2 hours later, I’ve got a local Visual Studio solution with implementations for Windows and Unix-like OSes. It was time to publish it on GitHub. So I did two things:
Now I needed to merge the two, so I hit publish in Visual Studio, and pointed it to GitHub.
That set the origin remote to my GitHub repo, but did not publish local changes,
as the local master branch and the remote one did not have a common ancestor.
“OK”, I though, “let’s fetch, make local master point to origin/master, from GitHub
then commit local files”. So I did
git fetch
git reset --hard origin/master

Back in Visual Studio all the source code is gone! So are the project files!
> git status
HEAD detached from c988afd
nothing to commit, working tree clean
If you ever did git reset without thinking before and recovered, you know a “magical”
command git reflog, which shows recent commits you worked with. To be precise it
shows which commits your repository was ever checked out at, so if you did
git checkout AAA then git checkout BBB then git reset --hard CCC it will show AAA;BBB;CCC,
and you can return to any of them using git checkout AAA, as long as you never had
git collect garbage.
For example:
> git reflog
...
c988afd HEAD@{4}: checkout: moving from master to c988afd
ea279fb HEAD@{5}: reset: moving to origin/master
c988afd HEAD@{6}: commit (initial): Add .gitignore and .gitattributes.
Unfortunately, git checkout c988afd did not restore the files, as I expected.

But why? The message for the initial commit gave a hint: I never checked in those files
before git reset, but they were staged. And, turns out, when you switch to a commit tree
with a different initial commit, git reset completely drops all the staged changes!
And Windows integrated backup - File History - by that time did not have a chance to make copies!
A quick search gave back Recover from git reset –hard on StackOverflow.
So I did git fsck --lost-found, which created a folder .git\lost-found\other
with a single file in it, containing just its own name: 97cc6b041928db3f3d282bbd30f5d1e276e47b19.
How that would help was not immediately clear:
> git show 97cc6b041928db3f3d282bbd30f5d1e276e47b19
tree 97cc6b041928db3f3d282bbd30f5d1e276e47b19
.gitattributes
.gitignore
IO.Links.sln
play/
src/
> git show 97cc6b041928db3f3d282bbd30f5d1e276e47b19 -- IO.Links.sln
tree 97cc6b041928db3f3d282bbd30f5d1e276e47b19
.gitattributes
.gitignore
IO.Links.sln
play/
src/
❯ git checkout 97cc6b041928db3f3d282bbd30f5d1e276e47b19
fatal: Cannot switch branch to a non-commit '97cc6b041928db3f3d282bbd30f5d1e276e47b19'
What is a git tree? I did not know.
The first search pointed to Git worktree, but
❯ git worktree move 97cc6b041928db3f3d282bbd30f5d1e276e47b19 "..\recover"
fatal: '97cc6b041928db3f3d282bbd30f5d1e276e47b19' is not a working tree
So a tree is not a working tree, OK.
Sigh.
Now searching git restore tree -"working"…
Bingo! (ls-tree)
❯ git ls-tree 97cc6b041928db3f3d282bbd30f5d1e276e47b19
100644 blob 1ff0c423042b46cb1d617b81efb715defbe8054d .gitattributes
100644 blob 4ce6fddec962ff3b86038d9939b6be5dfc1e6351 .gitignore
100644 blob c77dfcf2c002aae9fefa37273e9a82e290324ed1 IO.Links.sln
040000 tree 7d34ff63a2a130c9e8b7946e535ce83755db1ac7 play
040000 tree 91aa24f2b82c94d1ec4943b3747cd4d46a14db21 src
So there are blobs!

But no more *tree* commands.
More searching –> Git Restore
> git restore -s 97cc6b041928db3f3d282bbd30f5d1e276e47b19 -S -W
git: 'restore' is not a git command. See 'git --help'.
The most similar command is
remote
o_O but it is right there, in docs!
> git --version
git version 2.17.1
Ah. Docs are for version 2.23.0
choco install git
git --version
git version 2.23.0.windows.1
Finally:
> git restore -s 97cc6b041928db3f3d282bbd30f5d1e276e47b19 -S -W -- .
> git status
HEAD detached at c988afd
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
new file: IO.Links.sln
new file: play/Program.cs
new file: play/play.csproj
new file: src/IFileSystemLinks.cs
new file: src/Links.csproj
new file: src/Symlink.cs
new file: src/UnixLinks.cs
new file: src/WindowsLinks.cs
1AM
> git fsck --lost-found
> ls .\.git\lost-found\other
> git restore -s HASH_FROM_OTHER -S -W -- .
Project is restored and out on GitHub and NuGet: IO.Links - cross-platform symlink and hardlink management for .NET. (really: untested symlink creation only v0.0.1 at the time of the post).
As Ape3000 mentioned in the Reddit thread, updating git is not necessary.
git restore can be replaced with a variant of checkout:
# git checkout (-p|--patch) [<tree-ish>] [--] [<paths>…]
> git checkout HASH_FROM_OTHER -- .
Look at this Python trying to pretend to be your favorite language:
var = await.add(item)
switch(hello)
Of course the whole thing from building and training a deep convolutional network to the cross-platform UI will be written in .NET + TensorFlow.

Advanced-level tutorial on training a deep convnet to classify language from code fragments
Normally to process a sequence of any kind (in this case - characters), one would use an LSTM - long-short term memory network. However, getting an LSTM network to recognize a programming language of an entire file is too easy and boring.
Instead, Not C# AI will take as input a 64 by 64 block of characters from a text file, starting at an arbitrary position.
For example, this file
Accelerate* AccelerateFactory::Create(
int sample_rate_hz,
size_t num_channels,
from position (2,5) will look like this:
nt sample_rate_hz,
ize_t num_channels,
If a file/line ends too soon, the rest will be padded with space characters to make a full 64 by 64 block.
Every character will be converted to 0-255 range, and the whole input will look like a 64x64 grayscale image. You can see an example in the center of the pic below. Text on the right helps to understand which part of the code it represents, when you move the starting point.

Now try to guess the language from this image :)
HINT: there’s a single character in 2nd line from the last
Turned out my Projects folder has plenty of code with the following extensions: .cs, .py,
.h, .cc, .c, .tcl, .java, .sh, many coming from various open source libraries.
I also downloaded ~5 top trending GitHub repositories to have
some variety in the code styles.
All files needed some preprocessing on load: replaced tab character with spaces, and any characters with code above 255 with underscores (so that each character took exactly 1 byte, sorry, Unicode). Also replaced all other non-newline whitespace characters with code 255 to make them stand out.
I set aside 10% files of each type for validation. They are used at the end of the training to ensure the model does not just learn patterns specific to the files I train it on.
There were several thousand of files of each type, more of some, less of others. To ensure the model will
not be biased towards more popular languages, for each file type the training code samples ~50,000 64x64 blocks,
no matter how many files of this type there are. The process is simple: first, pick a random file with
specific extension, then pick a random line and column number to start sample from, then copy a 64x64 block of
characters from that position into a byte array, containing training samples.
Picking a file first ensures large files will not be overrepresented. The process is repeated
50,000 times for each extension to obtain enough samples (sampling code).
So inputs are 64x64 byte arrays, where character code simply turns into brightness of the “pixel”. In the end the network will only see the image in the center as input. Text on the right helps to understand which part of code it represents. Try to guess the language from that image, ha!
2D block picture-like representation suggests to use a convolutional network architecture. One of the recent ones is called ResNet. Not C# will use a simplified version.
ResNet consists of blocks, which stack 3 convolutional layers,
connected by batch normalization
with a variant of ReLU activation.
The output of the stack is concatenated with the input before the last activation, which is called
skip-connection. Skip-connection is there to help errors propagate to the blocks, that are closer
to the image input, than to the classifier output. The block layers are composed in the CallImpl
function.
The ResNet block code is adopted from the official TensorFlow tutorial for composing layers.
public class ResNetBlock: Model {
const int PartCount = 3;
readonly PythonList<Conv2D> convs = new PythonList<Conv2D>();
readonly PythonList<BatchNormalization> batchNorms = new PythonList<BatchNormalization>();
readonly PythonFunctionContainer activation;
readonly int outputChannels;
public ResNetBlock(int kernelSize, int[] filters,
PythonFunctionContainer activation = null)
{
this.activation = activation ?? tf.keras.activations.relu_fn;
for (int part = 0; part < PartCount; part++) {
this.convs.Add(this.Track(part == 1
? Conv2D.NewDyn(
filters: filters[part],
kernel_size: kernelSize,
padding: "same")
: Conv2D.NewDyn(filters[part], kernel_size: (1, 1))));
this.batchNorms.Add(this.Track(new BatchNormalization()));
}
this.outputChannels = filters[PartCount - 1];
}
public override dynamic call(
object inputs,
ImplicitContainer<IGraphNodeBase> training = null,
IEnumerable<IGraphNodeBase> mask = null)
{
return this.CallImpl((Tensor)inputs, training?.Value);
}
object CallImpl(IGraphNodeBase inputs, dynamic training) {
IGraphNodeBase result = inputs;
var batchNormExtraArgs = new PythonDict<string, object>();
if (training != null)
batchNormExtraArgs["training"] = training;
for (int part = 0; part < PartCount; part++) {
result = this.convs[part].apply(result);
result = this.batchNorms[part].apply(result, kwargs: batchNormExtraArgs);
if (part + 1 != PartCount)
result = ((dynamic)this.activation)(result);
}
result = (Tensor)result + inputs;
return ((dynamic)this.activation)(result);
}
public override dynamic compute_output_shape(TensorShape input_shape) {
if (input_shape.ndims == 4) {
var outputShape = input_shape.as_list();
outputShape[3] = this.outputChannels;
return new TensorShape(outputShape);
}
return input_shape;
}
...
}
And the model itself is just a sequence of ResNet blocks with some pooling operations in-between + a fully-connected (Dense in TensorFlow) softmax layer to output “probabilities”:
public static Model CreateModel(int classCount) {
var activation = tf.keras.activations.elu_fn;
const int filterCount = 8;
int[] resNetFilters = { filterCount, filterCount, filterCount };
return new Sequential(new Layer[] {
new Dropout(rate: 0.05),
Conv2D.NewDyn(filters: filterCount, kernel_size: 5, padding: "same"),
Activation.NewDyn(activation),
new MaxPool2D(pool_size: 2),
new ResNetBlock(kernelSize: 3, filters: resNetFilters, activation: activation),
new ResNetBlock(kernelSize: 3, filters: resNetFilters, activation: activation),
new ResNetBlock(kernelSize: 3, filters: resNetFilters, activation: activation),
new ResNetBlock(kernelSize: 3, filters: resNetFilters, activation: activation),
new MaxPool2D(),
new ResNetBlock(kernelSize: 3, filters: resNetFilters, activation: activation),
new ResNetBlock(kernelSize: 3, filters: resNetFilters, activation: activation),
new MaxPool2D(),
new ResNetBlock(kernelSize: 3, filters: resNetFilters, activation: activation),
new ResNetBlock(kernelSize: 3, filters: resNetFilters, activation: activation),
new AvgPool2D(pool_size: 2),
new Flatten(),
new Dense(units: classCount, activation: tf.nn.softmax_fn),
});
}
I also applied a 5% dropout to the input for regularization (the first in sequence): it prevents model from memorizing exact lines of code from the training set by masking different random characters out in different training iterations.
Part of the resulting model graph from TensorBoard:
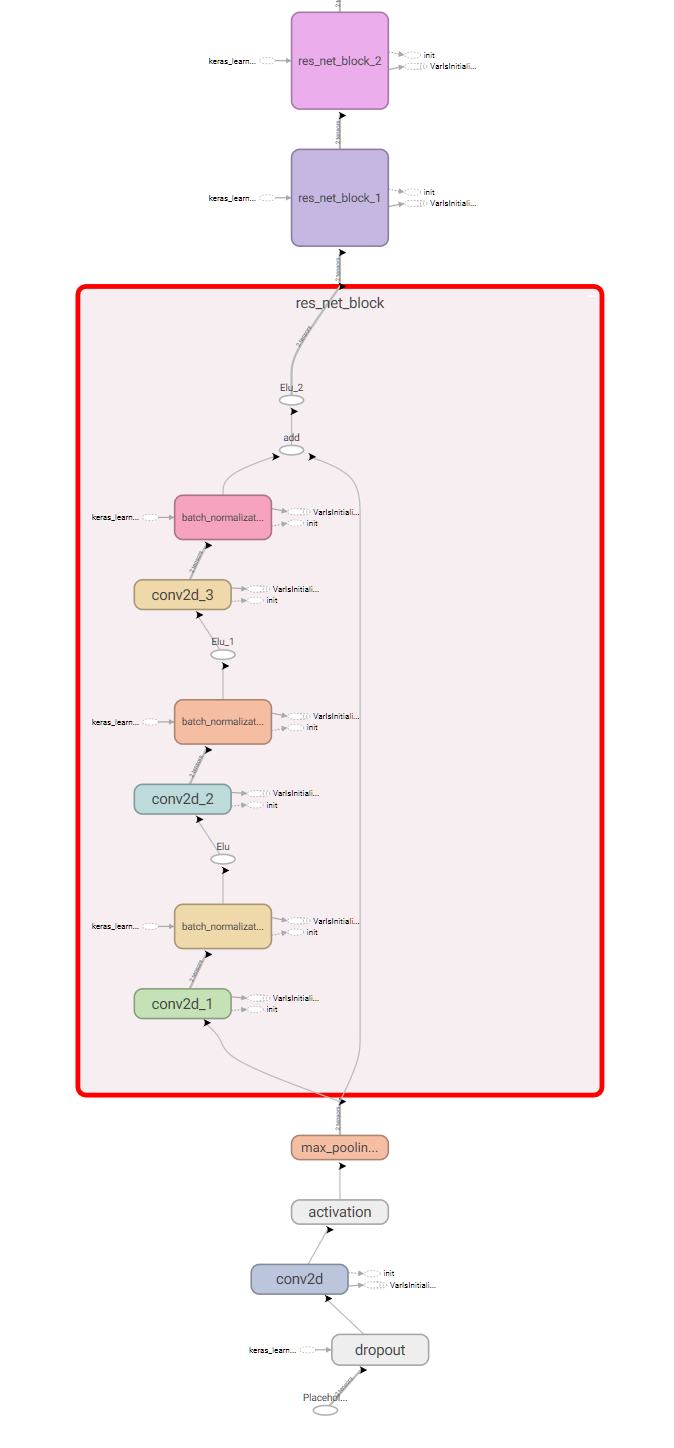
So the model is built, training inputs are layed one after another in a giant byte array.
All that is left is to specify loss function (since we are classifying between several languages,
we will use sparse_categorical_crossentropy), and an optimizer (Adam). And start training:
model.compile(
optimizer: new Adam(),
loss: tf.keras.losses.sparse_categorical_crossentropy_fn,
metrics: new object[] { "accuracy" });
model.build(input_shape: new TensorShape(null, Height, Width, 1));
model.fit(@in, expectedOut,
batchSize: this.BatchSize, epochs: this.Epochs,
callbacks: new ICallback[] {
checkpointBest,
tensorboard,
}
);
This also uses TensorFlow Keras callbacks:
Here you can see the training progress:
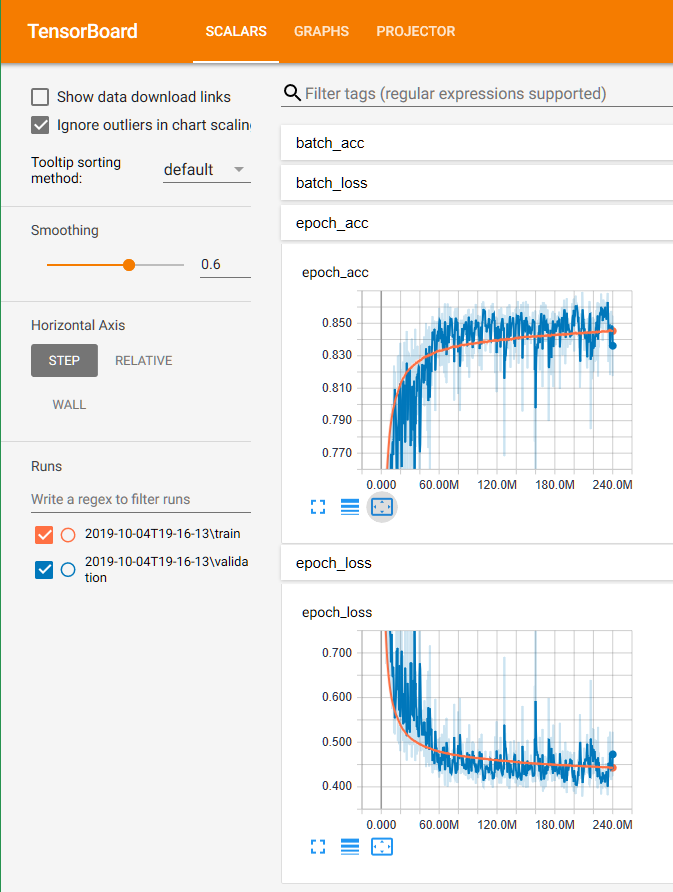
The complete training code can be found here.
When I started with TensorFlow 1.10, after some training the model accuracy would drop to ~0.125,
which is the same, as if the model would pick random answer all the time. After spending
a couple of days debugging my code and tweaking the model to avoid potential weight infinities,
I figured out the issue was actually caused by a nasty bug in TensorFlow 1.10’s
BatchNormalization layer. So I had to install TensorFlow 1.14 alongside 1.10 and use it instead
(see how to).

Also, the original model did not have the dropout layer right after the input, so it was overfitting, until I added one.
After about 2 days of training on my GPU, I got a model with ~86% accuracy.
E.g. given a 64x64 block of text from a code file, it would recognize the language
correctly in ~86% cases, which is pretty good, considering C is similar to C++,
and they are both could be in .h header files. Also Java and C# copy each other.
As seen on the graphs above, the validation accuracy did not go up much after ~100M batches, so I could have stopped training after ~20 hours. Also, the training code could be optimized by using slightly larger batch sizes, and switching to 16-bit floats on GPUs that support them.
I published the trained weights to GitHub, so you don’t have to train from scratch, if you just want to play with it.
That was the easy part of Not C#: I followed Avalonia’s official tutorial.
A couple of Grids, TextBlocks and some event wiring, and the app was able to load
code files, and use TextBox cursor position to select the starting point
of a 64x64 block of characters.
It also used cross-platform System.Drawing.Common NuGet package to render a nice image,
that network would see as the input. It worked great on Windows out of the box,
but on Mac I had to install mono-libgdiplus following this advice:
brew install mono-libgdiplus
NOTE: I had to use TensorFlow 1.14 for inference as well.
Also remember, that any input to the pretrained model must be processed the same way the training data was: Unicode characters replaced, and whitespace set to 255.
Look, it is C#!
Not C# demonstrates how to design and train a deep convolutional neural network with C# and TensorFlow. High-level Keras API is used to describe the model, and some OOP helps to abstract its building blocks away.
The pre-trained network can be used in a cross-platform UI app to load text files, and classify the programming language a block of text is written in.
The full up-to-date code of Not C# can be found on GitHub. Also, pretrained weights for v1.
]]>namespace, which by default adds 4 characters, and
then another 4 characters from the actual class you are
trying to define.
Take a look at this GitHub screenshot on my laptop for
a simple pull request:
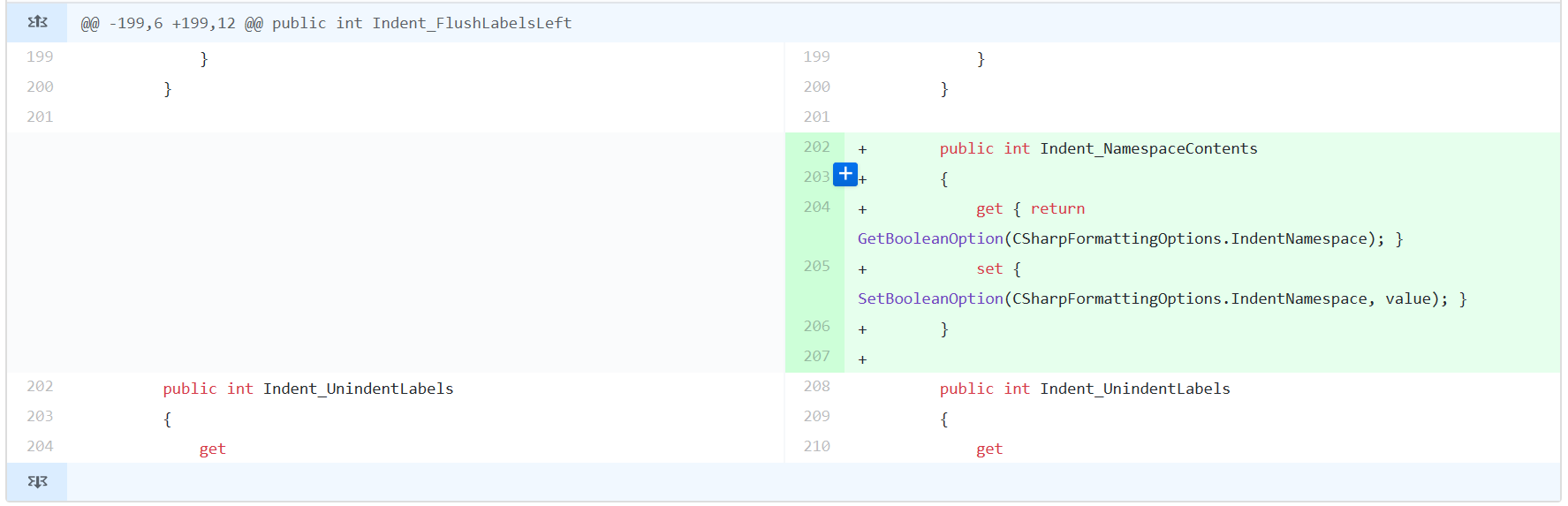
The getters and setters for the property had to be wrapped, because the lines are too long.
Since I had some spare time during today’s ML developers summit in Google Kirland, I decided to fix it. And it ended up pretty easy to do.
After cloning Roslyn and firing up
Roslyn.sln in Visual Studio, I quickly found a property named
IndentSwitch-bla-bla in the code. (I knew what to search
for, as there’s an option already for indenting switch
contents in Visual Studio).
Searching for references to this property gave back only
about 10 places, of which only one was an actual
implementation in the Roslyn formatting engine. As it
turned out, I only needed to add a simple if branch
that skips indent procedure for a certain AST node type:
NamespaceDeclarationSyntax if the option is turned off.
The rest of the changes are unit tests, and view model
construction to actually show a setting in Visual Studio.
All that took under an hour. Check out the result: pull request.
Once it is released with Visual Studio, I am planning to
switch that setting off on my machines and in .editorconfig.

Some projects successfully migrated to GitHub or VSO, but there were still quite a few, which I did not touch in years. Several of them the naive me from 2010 even considered to have commercial potential, so they were private repositories. Soon, of course, I will share them all (but won’t tell you which is which).
Where you can find my attempt to add support for typeclasses and higher-kinded polymorphism to F#, which even worked at least in part, if you believe this commit message.
Attempts to do it were actually preceded by a pure library implementation, which is briefly discussed here.
In the experiment, I wanted to get the feature in with minimal changes to the compiler to make a proof of concept, as the F# compiler source is very hard to follow. So the syntax was suboptimal, however quite readable (from the abovementioned commit):
/// This is 2D vector, that can print itself via Show<'a>.Print
type Vector2D<'a>(x: 'a, y: 'a) =
typeclass show = Show<'a>
typeclass t = Repeatable<'a>
member this.Times(n) =
Vector2D(x.Times(n), Times(y, n))
member this.Print() =
Print x
Note, that GitHub’s code highlighter does not recognize typecalss as a keyword. It is because F# compiler still does not have that feature.
Similarly to Go’s interfaces, you’d never have to explicitly state, that 'a actually implements Show. The implementation would be wired at runtime, and for the compile time a special diagnostic would actually check, that 'a you passed has all the necessary members.
Unfortunately, I stopped using F#, because the tooling around it is quite far behind what ReSharper and now even Roslyn do for C#. The last commit to that repository was on April 1st, 2012.
This project actually found its home on GitHub, because some day in 2014 a person pinged me about using LLVM binding for C#, which I had developed for it, so I migrated both.
CodeBlock was my LLVM playground. The project was supposed to be an implementation of .NET runtime, written mostly in .NET itself rather than C, using LLVM as a backend. Quite similar to CoreCLR in nature. I wrote most of it during my student years.
In this example assertTest would compile & execute code in between <@ and @>, e.g. FactorialMethod:
static member FactorialMethod(n) =
let mutable result = 1
let mutable i = 2
while i <= n do
result <- result * i
i <- i + 1
result
[<TestMethod>]
member this.FactorialNeg() =
[ -2; -1; Int32.MinValue ]
|> List.iter(fun n -> assertTest <@ PrimitiveOps.FactorialMethod(n) @>)
[<TestMethod>]
member this.FactorialZero() =
assertTest <@ PrimitiveOps.FactorialMethod(0) @>
It was using Mono.Cecil to read method bodies bytecode that .NET uses (similar to Java bytecode), and then use LLVM 3’s JIT APIs to convert it to native x64 or x86 code before execution.
As far as I remember (and judging by other contents of the unit tests folder), it went as far as to have most of unmanaged CLR features working, including pointers and struct generic types. Garbage collector would be the next step and some of the “object model” was already defined. The last meaningful commit to that repository was on August 7th, 2013.
I am sure some readers here have seen the infamous show “Silicon Valley”. In 2017 season it was revealed, that Pied Piper is to build what Peter Gregory planned all along: a truly decentralized Internet. Well, CoreCloud was in some sense a 2010 take on that dream with trustless compute, and P2P IPv6 which was surely supposed to take over the world by 2015.
The goal of the project was to make it super simple to run decentralized trustless computations in .NET (which, by the way, had all the necessary components back then). Here is how it worked: first, you would declare a class, whose code you want to run on many machines, and its interface like this:
public class PrimeTest: IPrimeTest
{
public bool[] Test(int start, int count)
{
var nums = Enumerable.Range(start, count);
return nums.Select(IsPrime).ToArray();
}
internal bool IsPrime(int num)
{
if (num < 2) return false;
for (int i = 2; i <= Math.Sqrt(num); i++)
{
if (num % i == 0) return false;
}
return true;
}
}
[ServiceContract]
public interface IPrimeTest
{
[OperationContract]
bool[] Test(int start, int count);
}
Then you would just create an instance of this class, and call its Test method in parallel like this:
const int ChunkSize = 1024;
var primeTest = ParallelObject<IPrimeTest>.Create<PrimeTest>();
var results = new ConcurrentDictionary<long, bool[]>();
Parallel.For(0, 1024, chunk
=> results[chunk] = primeTest.Test(chunk*ChunkSize, ChunkSize));
Behind the scenes CoreCloud would query a peer-to-peer network of people running CoreCloud on their machines, pick some of them, transmit the code of PrimeTest, and ask them to instantiate it for you in a sandbox (now that .NET feature is deprecated 😢). primeTest here will actually be a proxy generated by CoreCloud on the fly for IPrimeTest. Every call to Test in the Parallel.For loop CoreCloud would pick one of the remote instances of PrimeTest it created, and forward it there.
The project was to be demoed on a graphics engine, which would use nearby computers to deliver real-time full HD ray-tracing-based rendering in a very similar manner with Engine.TraceRays replacing PrimeTest.Test in the example above. The last commit to the original Mercurial repository was on May 8th, 2011.