
Native Sparse Attention
Wow, just read the #DeepSeek Native Sparse Attention paper, and they basically do exact same things I considered most promising from experiments back in 2022.
On the screenshots:
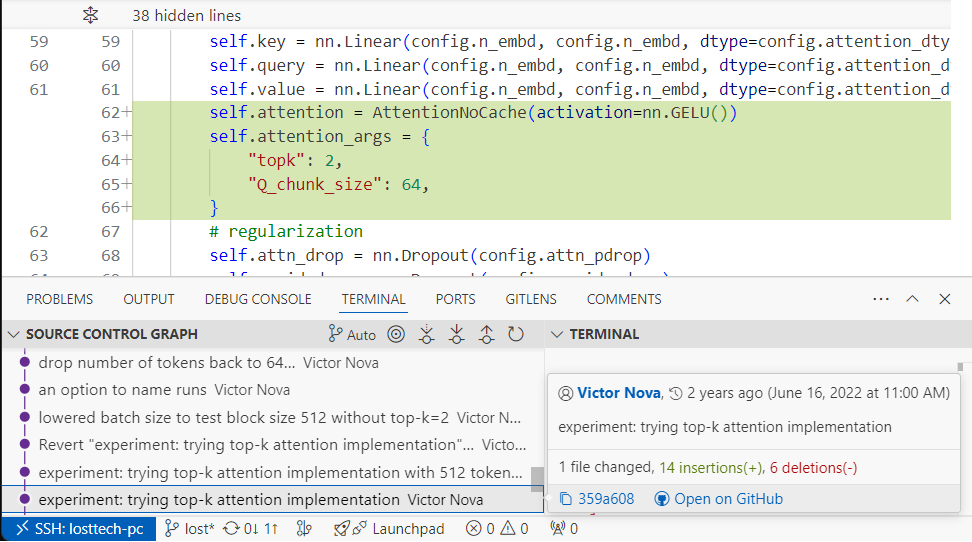
- top-k settings from an experiment that mirrors their Token Selection (section 3.3.2 of the paper)
- causal mask calculation for what they call Token Compression (section 3.3.1 of the paper)
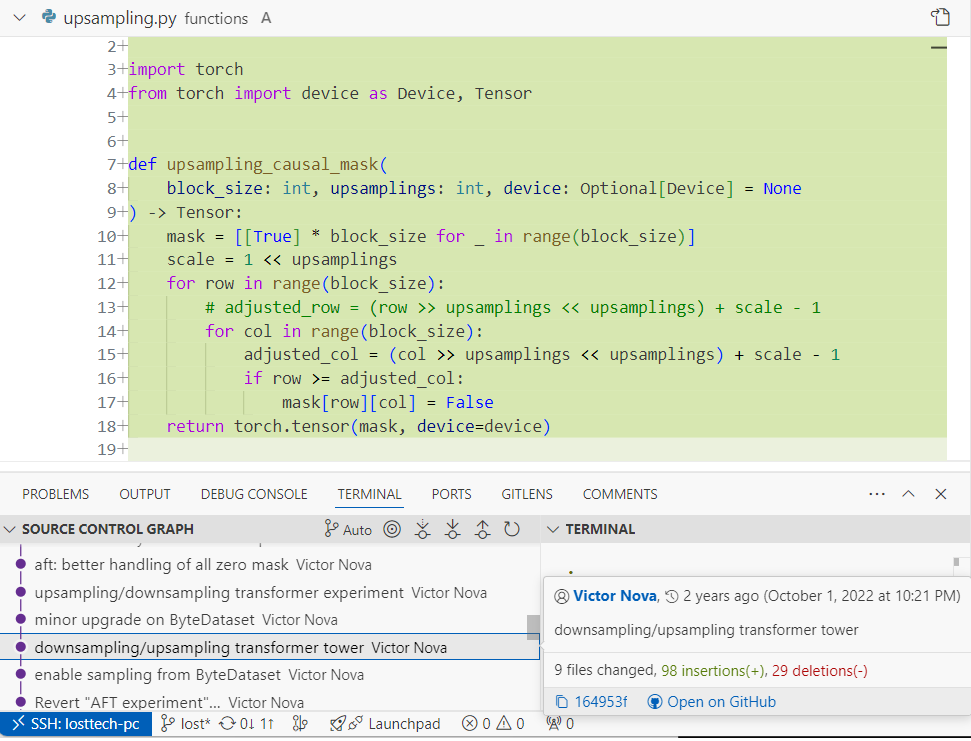
As far as I can see combining these + the regular attention + custom CUDA kernels are the main contributions from the paper.
Maybe I should go back to research. The whole point of trying to build a startup was to be able to scale the research to larger models, but it appears gains from architecture improvements can be verified on pretty small ones (I did all my experiments on a single RTX 3090, most of the models in ~100MB range).
Written on March 2, 2025